Textbook Question
Variance of Roller Coaster Speeds The standard deviation of the sample values in Exercise 1 is 43.1 km/h. What is the variance (including units)?

 Verified step by step guidance
Verified step by step guidance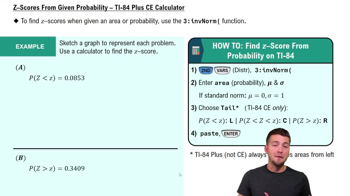
 06:31
06:31 08:45
08:45 05:53
05:53Variance of Roller Coaster Speeds The standard deviation of the sample values in Exercise 1 is 43.1 km/h. What is the variance (including units)?
Why Divide by ? Let a population consist of the values 9 cigarettes, 10 cigarettes, and 20 cigarettes smoked in a day (based on data from the California Health Interview Survey). Assume that samples of two values are randomly selected with replacement from this population. (That is, a selected value is replaced before the second selection is made.)
c. For each of the nine different possible samples of two values selected with replacement, find the variance by treating each sample as if it is a population (using the formula for population variance, which includes division by n); then find the mean of those nine population variances.
Why Divide by ? Let a population consist of the values 9 cigarettes, 10 cigarettes, and 20 cigarettes smoked in a day (based on data from the California Health Interview Survey). Assume that samples of two values are randomly selected with replacement from this population. (That is, a selected value is replaced before the second selection is made.)
d. Which approach results in values that are better estimates of part (b) or part (c)? Why? When computing variances of samples, should you use division by n or
Percentile Use the weights from Exercise 1 to find the percentile for 3647 mg.
Roller Coaster z Score A larger sample of 92 roller coaster maximum speeds has a mean of 85.9 km/h and a standard deviation of 28.7 km/h. What is the z score for a speed of 34 km/h? Does the z score suggest that the speed of 34 km/h is significantly low?
Estimating s The sample of 92 roller coaster maximum speeds includes values ranging from a low of 10 km/h to a high of 194 km/h. Use the range rule of thumb to estimate the standard deviation.