Textbook Question
Normal Distribution If the following data are randomly selected, which are expected to have a normal distribution?
a. Weights of Reese’s Peanut Butter Cups

 Verified step by step guidance
Verified step by step guidance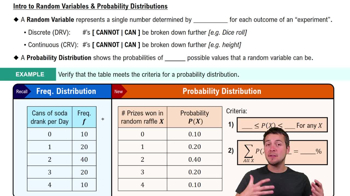
 07:09
07:09 04:48 04:48
04:48 04:48Normal Distribution If the following data are randomly selected, which are expected to have a normal distribution?
a. Weights of Reese’s Peanut Butter Cups
More IQ Scores The population of IQ scores of adults is normally distributed. If we obtain a voluntary response sample of 5000 of those IQ scores, will a histogram of the sample be bell-shaped?
Computers As a quality control manager at Texas Instruments, you find that defective calculators have various causes, including worn machinery, human error, bad supplies, and packaging mistreatment. Which of the following graphs would be best for describing the causes of defects: histogram; scatterplot; Pareto chart; dotplot; pie chart?
Normal Distribution If the following data are randomly selected, which are expected to have a normal distribution?
d. Exact volumes of Coke in 12 oz cans
In Exercises 1–5, use the data listed in the margin, which are magnitudes (Richter scale) and depths (km) of earthquakes from Data Set 24 “Earthquakes” in Appendix B
[Image]
Data Type
b. For the listed earthquake depths, are the data categorical or quantitative?
Tornado Alley A stemplot of the same data summarized in Exercise 1 is created, and one of the rows of that stemplot is 3 | 000144669. Identify the values represented by that row of the stemplot.